字符串匹配(BF算法、RK算法、BM算法)
目录:一、BF算法、RK算法二、BM算法

引入:在字符串匹配算法的前面,我们分别介绍一下暴力算法BF算法,利用哈希值进行比较的RK算法,以及尽量减少比较次数的BM算法:
一、BF算法和RK算法:
举例:两个字符串:主串: a b b c e f g模式串: b c e
第一轮,我们从主串的首位开始,把主串和模式串的字符逐个比较:
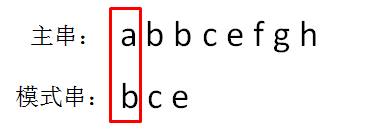
显然,主串的首位字符是a,模式串的首位字符是b,两者并不匹配。第二轮,我们把模式串后移一位,从主串的第二位开始,把主串和模式串的字符逐个比较:
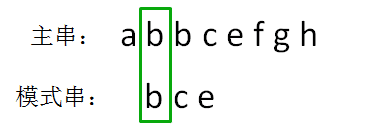
主串的第二位字符是b,模式串的第二位字符也是b,两者匹配,继续比较:主串的第三位字符是b,模式串的第三位字符也是c,两者并不匹配。
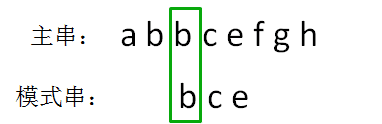
由此得到结果,模式串 bce 是主串 abbcefgh 的子串,在主串第一次出现的位置下标是 2:这就是BF算法(暴力算法)。
但是,这种算法在某些极端情况下效率很低,例如字符串aabbbbbbbbsbd和子串bd匹配。
假设主串的长度是m,模式串的长度是n,那么在这种极端情况下,BF算法的最坏时间复杂度是O(mn)。
BF算法的改进(RK算法):
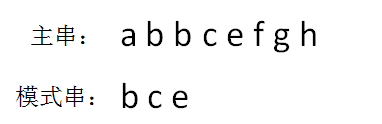
按位相加
这是最简单的方法,我们可以把a当做1,b当做2,c当做3…然后把字符串的所有字符相加,相加结果就是它的hashcode。bce = 2 + 3 + 5 = 10但是,这个算法虽然简单,却很可能产生hash冲突,比如bce、bec、cbe的hashcode是一样的。使用按位相加计算hash值,需要对相同的hash值的两个字符串进行一对一比较,若相同就是匹配成功,若是不能一一对应,则代表匹配失败。
转换成26进制数
既然字符串只包含26个小写字母,那么我们可以把每一个字符串当成一个26进制数来计算。bce = 2*(26^2) + 3*26 + 5 = 1435这样做的好处是大幅减少了hash冲突,缺点是计算量较大,而且有可能出现超出整型范围的情况,需要对计算结果进行取模。为了方便演示,这里我们采用的是按位相加的hash算法,所以bce的hashcode是10:
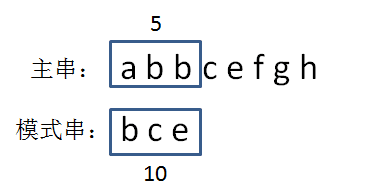
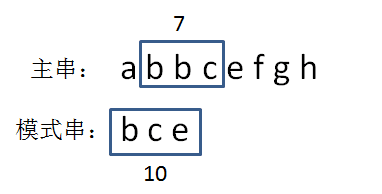
bce= 2 + 3 + 5 = 10:接着进行比较,显然10 ==10,两个hash值相等!这是否说明两个字符串也相等呢?
由于存在hash冲突的可能,我们还需要进一步验证。
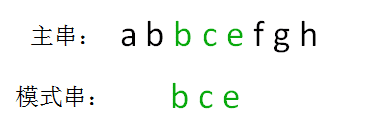


下面给出算法的代码实现:
public class 字符串匹配 { public static int strKarp(String str,String pattern) { int m=str.length(); int n=pattern.length(); int patternCode=hash(pattern); int strCode=hash(str.substring(0, n)); for(int i=0;i
BM算法:
坏字符规则:

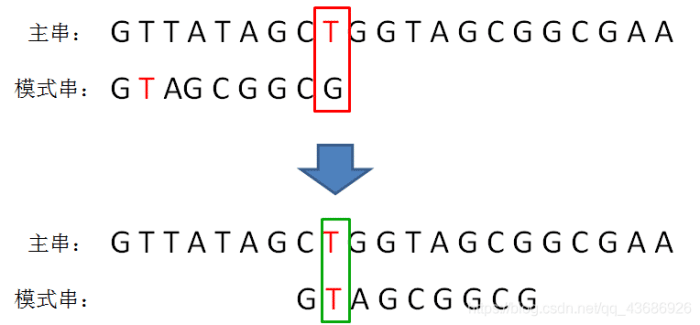
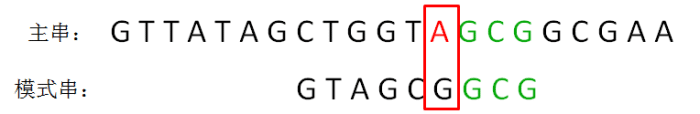
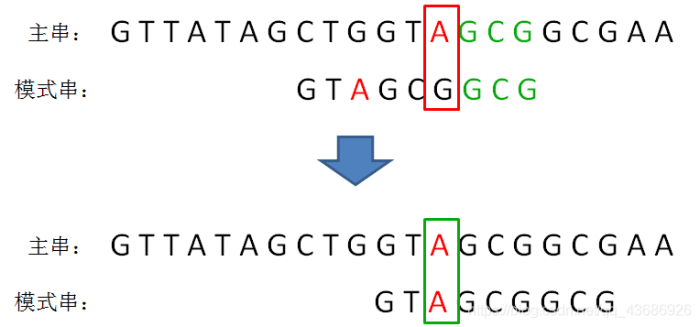
坏字符的规则代码编写:
public class 字符串匹配的坏字符规则 { public static int bM(String str,String pattern) { int sl=str.length(); int pl=pattern.length(); int start=0; while(start <= sl-pl) { int i;for(i = pl-1; i >= 0; i--) { if(str.charAt(start+i) != pattern.charAt(i)) { break; } if(i<0) {return start; } int charIndex=findChar(pattern,str.charAt(start+i),i); int off=charIndex>=0 ? i-charIndex : i+1; start += off; } } return -1; } private static int findChar(String pattern, char charAt, int index) { for(int i=index-1;i>=0;i--) {if(pattern.charAt(i) == charAt) { return i; } } return -1; } public static void main(String[] args) { String str="GBTTTATAGCTGGTAAGCGBGCGATA"; String pattern="GTAAGCG"; int index=bM(str, pattern); System.out.println("首次出现的位置是:"+index); }}
总结:字符串匹配各种算法的核心思想是:利用模式串中某个字符与主串不能匹配的时候,将模式串往后多滑动几位,以此来减少不必要的字符比较,提高匹配的效率。

 苏公安备32041202001599号
苏公安备32041202001599号